
On the fly thumbnails
Recently we were looking for a good solution when it comes to generating thumbnails on the fly. Obviously we don't want to serve the full size image and let the browser scale it. This would require the user to download the full image while it only needs a 100x100 version. That's a lot of wasted bandwidth if original size of the image is 1920x1080.
Our requirements
Avoid re-generation of thumbnails We don't want to scale the image down to the required size every time a user requests it. Once an image has been scaled, the result should be cached and the next time a user requests a thumbnail with the same size, the cached version should be served. This avoids burdening the CPU unnecessarily.
Minimal implementation overhead We don't wanna waste too much time on this. It is merely a optimization. It doesn't add any functionality besides speedy page loads. We also don't want the implementation to intrude too much into our code base. It should be easy to implement and easy to maintain.
No pre-rendering We don't want to generate/render the thumbnails whenever a new image is uploaded. We don't know exactly in which dimensions we're going to display the image yet. This might also change in the future when we adjust the design. If thumbnails would be generated/rendered when the image is uploaded, then we'd have to re-render them whenever we need them in a different size.
Minimal I/O overhead Most solutions we came across would store the generated thumbnail on disk. This means that you have I/O operations everytime the thumbnail is requested.
Must work well with a CDN We don't want every single request hitting our web server. A CDN is much more suited to deliver these "static" resources to the user. Large CDN's have edge nodes all over the world. They specialize in getting resources to the end user as quickly as possible. We take advantage of that.
In short: we want to get any image in any dimension whenever we want, while minimizing implementation and performance costs.
Possible solutions
We investigated various solutions before deciding on one. There are several packages out there that aim to solve these problems. We tried the following:
Some of these packages are very good. They are well designed, well tested and commonly used by the community. However, none of them fit all our requirements.
django-stdimage and others involve making changes to your models. easy-thumbnails for example requires pre-rendering your thumbnails.
Sorl for example allows one to use Redis as a meta-data store to avoid hitting your storage. However, in the end they would still store the thumbnails. It depends on your storage back-end of course, but in our case that would mean Amazon S3. An interesting feature, but not what we need.
We also considered using Cloudinary, but that involves having to upload our images to Cloudinary. Which is a unncesarry hassle.
So, what else?
Our solution is as following:
Implement a simple thumbnailer into our application that works like this:
GET http://ourwebsite.com/thumbnail/100x100/[image storage path]Which would take the specified image storage path, create a thumbnail of 100x100 in memory and return the result.
Ensure that requests never hit that URL directly, but always go through Amazon CloudFront.
That's it. The first time the image is requested:
https://ourapp.cloudfront.net/thumbnail/100x100/[image storage path]CloudFront will forward the request to our webserver, which will take the original image, generate a thumbnail of it and return it. CloudFront will from then on cache the result. The next time the same thumbnail is requested through CloudFront, it won't hit our web server anymore. Instead, CloudFront will serve the thumbnail it cached.
Our thumbnail generation code is quite simple. The excellent Pillow (fork of PIL - Python Imaging Library) library makes this real easy:
try:
with default_storage._open('myimage.png', 'rb') as image:
pil_image = Image.open(io.BytesIO(image.read()))
pil_image.thumbnail((128, 128))
thumbnail = io.BytesIO()
pil_image.save(thumbnail, 'jpeg')
except FileNotFoundError:
raise Http404('File not found: %s' % image_path)
with thumbnail:
return HttpResponse(
thumbnail.getbuffer(),
content_type='image/jpeg'
)So, what's happening here?
- We load the original image from
pathinto a buffer. - We instruct Pillow to create a thumbnail of 128x128.
- We instruct Pillow to "save" the resulting thumbnail in a buffer so we don't write it to disk.
- We return the thumbnail to the user.
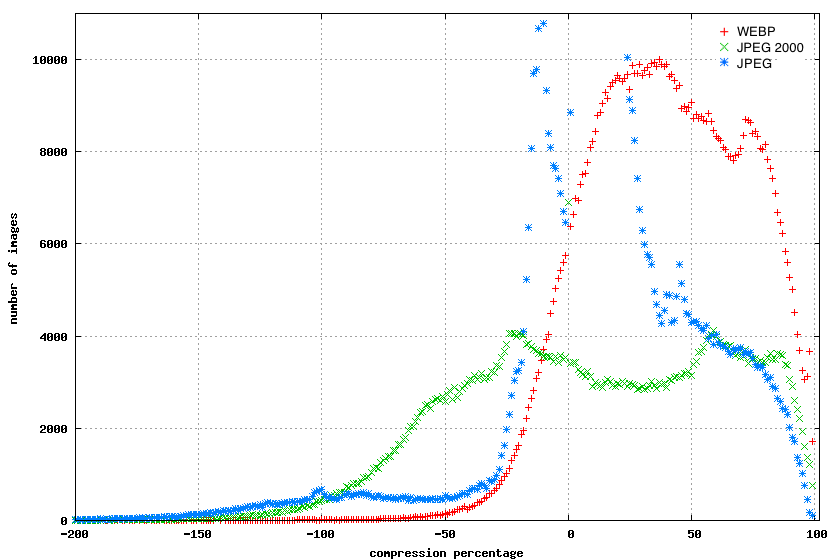
We chose to encode the resulting image in WebP since it is a much better compressor than JPEG/PNG:
However, older browsers and Internet Explorer do not support WebP. We chose to implement a fallback mechanism using the HTML5 <picture> element, which allows you to specify multiple sources for an image:
<picture>
<source type="image/webp" srcset="https://magic.cloudfront.net/thumbnail/100x100/webp/myimage.jpeg">
<img src="https://magic.cloudfront.net/thumbnail/100x100/jpeg/myimage.jpeg">
</picture>If a browser supports WebP, it will request the WebP version. If not, it will fall back to the JPEG version.
Security considerations
We implement the following to lower the probability of a Denial-Of-Service (DDOS) attack being successful:
- Only requests coming from CloudFront are allowed.
- We restrict the dimensions that can be requested.
Conclusion
We chose this approach over any of the other approaches we've explored because it trumps in:
- Simplicity
- Performance
We'll be monitoring the results of this decision once we go in production and report back on the results. Got any feedback? Let us know! We'd love to be proven wrong.